
Jean Auguste Dominique Ingres - Portrait d’une jeune femme (1766–1817), huile sur toile, 59.6 x 73.2 cm, Hull (UK), Ferens Art Gallery.
Cet article sera consacré à l’architecture de systemd.
Le cœur de systemd est basé sur quelques piliers : UDev et DBus qui permettent de mettre en place une approche évènementielle, les CGroup pour l’encapsulation des processus et le contrôle des ressources et plus récemment EBPF pour les métriques. Architecture de systemd - By Shmuel Csaba Otto Traian, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=28698339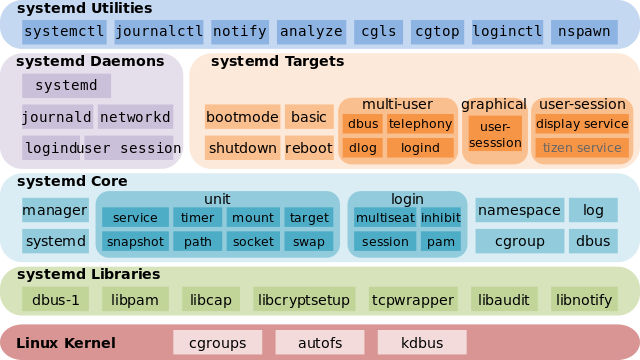
Il se base sur plusieurs principes forts que je vais tenter de détailler ci-dessous.
Retarder l’initialisation
L’un des objectifs initiaux du projet était d’améliorer le temps de démarrage des systèmes jugé à juste titre trop long.
Il faut garder à l’esprit qu’il a été pensé pour répondre à ces différents cas d’utilisation (serveur, station de travail, embarqué…). Si le temps de démarrage n’est (souvent) pas crucial pour un serveur, ce n’est absolument pas le cas pour une station de travail ou pour un mobile.
Pour arriver à cela plusieurs types d’unit sont chargés uniquement de l’activation des services lors de leur première utilisation. On peut citer les types : socket, path, automount …
Cela permet d’éviter de lancer un service trop tôt (bien souvent au démarrage) et ainsi optimiser le temps de d’initialisation.
Pour réaliser cela systemd utilise plusieurs méthodes d’activation :
Les Socket.
Le principe est assez simple et est largement inspiré de ce qui se faisait déjà sur inetd. Mais contrairement à ce dernier, de nombreux types de socket sont maintenant supportés : UNIX, INET, named pipes, netlink…
On peut résumer les étapes de la façon suivante :
- Des buffers sont alloués automatiquement au démarrage pour chaque service qui le demande.
- Lors d’un appel, ces buffers se remplissent jusqu’à une taille limite au-delà de laquelle l’écriture devient impossible. Dans ce cas le client se met alors en attente et l’appel devient bloquant (c’est ce qui se passe d’ailleurs lorsqu’il attend une réponse).
- Les descripteurs de fichiers sont scrutés et au premier message le service consommateur est démarré en parallèle.
- Enfin on lui transmet le(s) socket(s) en paramètres afin qu’il puisse les lire une fois initialisé. En cas d’échec de démarrage, rien n’est lu et le service peut être relancé sans pertes d’informations.
Néanmoins, attention le passage de sockets n’est pas un comportement “natif” sous Linux. Il faut donc que le service soit compatible avec systemd (c’est heureusement le cas de nombreux serveurs web entre autres).
Grâce à ce comportement, on peut non seulement activer un service au premier appel, mais également briser les chaines de dépendances entre services et paralléliser leur activation.
Par exemple dans le cas d’un service qui nécessite syslog : Il est possible de lancer les deux en parallèle, les messages syslog seront envoyés mis en attente dans le buffer avant d’être dépilé à l’initialisation complète de syslog.
UDev
UDev est un daemon qui permet d’exposer dans l’espace utilisateur les périphériques de façon dynamique. Il prend en charge le hot-plug mais aussi pour les périphériques classiques.
C’est un daemon qui écoute dans l’espace utilisateur les évènements publiés par le kernel via netlink (un socket entre le kernel et l’espace utilisateur).
Il fait ensuite la liaison entres les informations du sysfs et déclenche des règles spécifiques écrites par un administrateur.
Ce projet a acquis une telle importance qu’il fait maintenant partie à part entière de systemd.
Prenons un exemple concret de comment utiliser UDev avec systemd.
Tout d’abord nous pouvons écouter les évènements publiés par le kernel et UDev ainsi :
| |
Ce qui donne ce résultat lors de l’activation de bluetooth sur mon portable
| |
La première partie concerne la mise en route du récepteur bluetooth, la seconde la connexion du casque audio.
On voit apparaître un nouveau device sous l’arborescence /devices/virtual/input/input24.
Ensuite on cherche à écrire une règle UDev qui va s’activer uniquement pour ce périphérique.
Pour cela il nous faut donc chercher les attributs discriminants dans les événements UDev que l’on peut voir à l’aide de la commande (attention les chemins UDev sont toujours relatifs aux répertoires /sys ou /dev/):
| |
Je serais bien incapable d’expliquer la signification de tous les attributs, par contre je peux en reconnaître quelque uns comme le nom et son adresse (qui me semble assez unique) :
| |
Ensuite avec ces informations on est en mesure d’écrire une règle appropriée pour sélectionner ce matériel de la façon suivante :
| |
Les premiers éléments servent à sélectionner les attributs dans les événements UDev qui vont déclencher la règle : le nom du system, l’attribut nom et son adresse.
Puis la partie importante pour l’intégration avec systemd est TAG+="systemd.
Ce tag permet de marquer le périphérique pour être interprété comme une unit “.device”.
C’est d’ailleurs la seule chose à faire pour faire fonctionner cette règle avec systemd.
J’ai ajouté l’attribut SYSTEMD_ALIAS= car le chemin du périphérique n’est pas prévisible (/sys/devices/virtual/input/input<X>).
Comme le nom de la unit est déterminé par son chemin il est plus simple qu’il soit toujours le même.
Maintenant ce device va apparaître systématiquement sous le nom sys-devices-virtual-input-lg_tone_fp9.device.
On est donc en mesure d’écrire un service qui va s’activer lors de la présence de ce device.
| |
Il existe également la possibilité d’activer un service directement à partir d’une règle UDev.
D-Bus
D-Bus est un nouvel framework d’IPC (inter-process communication) qui permet de communiquer de façon standardisée entre différents services. Il permet - entre autre - de faire :
- du RPC (Remote Procedure Call) en offrant une sérialisation standardisée.
- de sécuriser les communications via un mécanisme d’autorisation.
- de l’activation à la demande via un système de nommage.
- de la découverte de service
- …
Systemd est complètement intégré avec D-Bus (l’architecture des deux produits est par ailleurs assez similaire).
Il est ainsi possible d’interagir avec systemd uniquement via les API D-BUS.
Pour voir les services exposés par DBus il suffit de taper la commande :
| |
On peut également voir l’ensemble des propriétés d’un service
| |
Puis pour lister les propriétés, méthodes d’un service (systemd ici) :
| |
Cela donne accès à l’ensemble des objets accessibles via D-BUS (c’est aussi un bon moyen pour connaître les valeurs des propriétés par défaut).
On peut également écrire un service activable lors de la présence d’un bus de la façon suivante :
| |
Bref les possibilités sont impressionnantes, tellement l’intégration des deux systèmes est poussée.
Inotify
Inotify est un mécanisme qui permet d’observer les actions sur un système de fichiers.
Il permet de s’abonner à un répertoire ou fichier et de recevoir les types d’évènements suivants :
- IN_ACCESS : le fichier est accédé en lecture ;
- IN_MODIFY : le fichier est modifié ;
- IN_ATTRIB : les attributs du fichier sont modifiés ;
- IN_OPEN : le fichier est ouvert ;
- IN_DELETE : un fichier a été supprimé dans le répertoire surveillé ;
- IN_CREATE : un fichier a été créé dans le répertoire surveillé.
- …
En symétrie nous allons donc retrouver sous systemd les fonctions suivantes PathExists=, PathChanged=, PathModified=, DirectoryNotEmpty=
Attention - comme spécifié dans la documentation - inotify souffre de certaines limitations, il n’est par exemple pas possible de scruter les évènements produits par une machine distante sur une filesystem en réseau (type NFS).
Autofs
Autofs est un module du kernel qui permet de retarder le montage d’un FS. Pour cela il crée des mount-trap (des dentry avec un attribut particulier) qui au premier accès (au-delà du stat) va faire appel à un daemon - dans notre cas systemd - qui va effectuer le montage. Par la suite le filesystem pourra être utilisé comme un FS habituel.
Cela offre deux avantages :
- alors que l’initialisation classique attend le montage de tous les FS (qui dans le cas de FS en réseaux peut être assez long), ici nous n’avons plus à attendre cette étape.
- cela permet également de paralléliser les montages.
Paralléliser
On l’a vu plus haut - en plus du chargement à la demande - beaucoup de composants facilitent la parallélisation des actions et font ainsi gagner en efficacité.
De son côté systemd se base sur son modèle de dépendances et cherche à minimiser les points de synchronisations qui ralentissent le démarrage.
Pour cela il va construire un arbre de dépendances pour pouvoir lancer un maximum de services en parallèle en ayant à attendre uniquement ceux qui lui sont nécessaires.
Pour arriver à cela des ordonnancements - souvent implicites - sont mis en place suivant différents critères afin de garantir la bonne cohérence des actions (c’est d’ailleurs souvent la partie la plus complexe à mettre en œuvre à mon avis).
Pour illustrer mes propos voici le graphique de démarrage, pour atteindre la default.target :
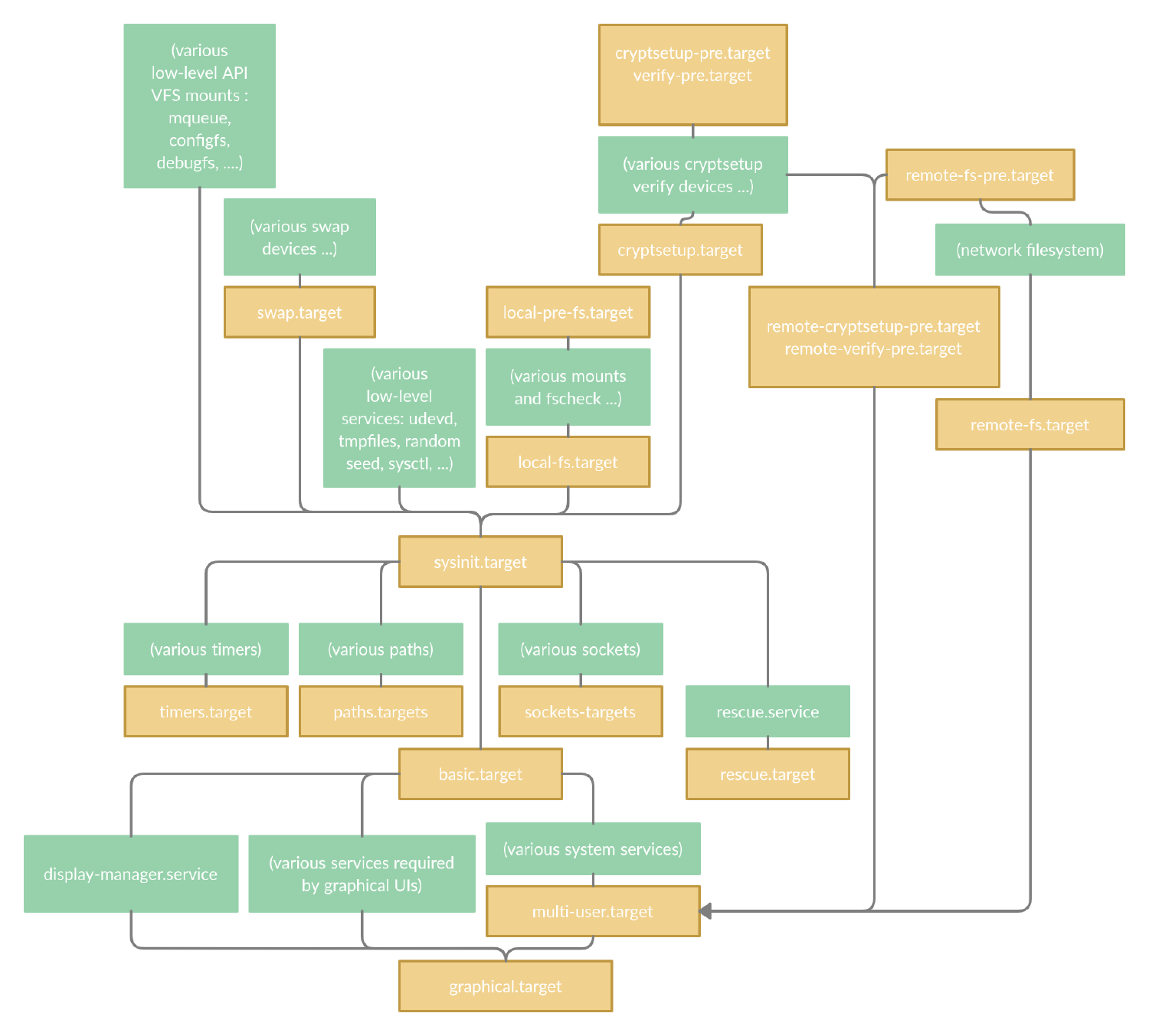
Bootup graph
À noter quelques points qui me semblent importants :
- Lorsque systemd active un nombre de unit - et si aucun ordre n’est spécifié - elles sont faites en parallèle.
- Par défaut les services s’exécutent après la
sysinit.target(ou à labasic.targeten mode user). Pour passer outre il faut ajouter la propriétéDefaultDependencies=false.
Comme souvent des outils sont mis à disposition pour nous aider :
On peut citer systemd-analyse plot (en SVG) ou systemd-analyse dot (au format DOT) qui permettent de générer des représentations graphiques de ce que nous venons d’aborder.
L’utilisation des cgroups
Contrairement à ce que l’on pourrait croire le cgroups ne sont pas utilisés (du moins au départ) dans systemd pour le contrôle de resources, mais pour le contrôle des processus.
Il s’avère en pratique compliqué de terminer correctement un service ayant un nombre de processus forkés important.
Pour tenter de comprendre le problème, revenons sur quelques notions UNIX :
Un processus est rattaché à une session.
Par convention le SID il est égal au PID du premier membre de la session, le “session leader”.
La session peut être un terminal, une connexion ssh… ou autre.
Dans une session on trouve un certain nombre de groupes de processus.
Le PGID est égal au PID du premier membre du groupe le “process group leader” (vous voyez la logique).
Au sein d’une session un seul groupe peut être au premier plan.
Un processus PID a (presque) toujours un parent et hérite de certains de ses attributs (UID, GID, SID, PGID…). Il est lui-même composé de plusieurs threads.
Si en théorie c’est simple, en pratique, c’est assez compliqué : liberté d’implémentation, différences entre les systèmes UNIX, manque de syscall… Tout cela a fait qu’il est difficile de suivre correctement l’ensemble des processus issus de différents forks.
Par exemple l’une des techniques couramment utilisées pour lancer un processus en arrière-plan (daemon) est la technique dite du “double-fork”. Elle consiste à effectuer les opérations suivantes :
- Un premier
fork()pour créer un processus enfant de façon classique. - Qui va ensuite appeler
setsid(0)pour se détacher de la session courante. - Pour enfin effectuer un nouveau
fork()pour que ce changement soit pris en compte. Le processus nouvellement créé est ainsi rendu orphelin et ne peut plus interagir avec la session d’origine (et vice versa).
Du point de vue d’un init manager, le problème est qu’il n’a connaissance que du PID issu du retour du premier fork, et pas de celui issu du second et éventuellement des autres processus forkés.
Une parade consistait à stocker le résultat du second fork dans un fichier PID file pour pouvoir le retrouver. Cette méthode est tout à fait valide, mais souffre de limites en cas de nouveau fork et est de plus très dépendante de l’implémentation qui en est faite.
On peut me faire remarquer que systemd utilise aussi des pid file, oui mais :
- c’est surtout pour assurer la rétrocompatibilité avec les anciens scripts.
- ce n’est pas exactement utilisé pour la même fonction (principalement par le watchdog).
Pour pallier ce problème, systemd utilise les CGroup.
Présent depuis longtemps dans le kernel Linux les CGroups sont prévus pour régler ce type de problème. À la différence d’autres propriétés un processus ne peut pas s’échapper d’un CGroup (à moins de créer un nouveau sous CGroup qui reste néanmoins toujours le descendant du parent). Il est de plus assez aisé de recenser l’ensemble des processus d’un CGroup.
Systemd a donc décidé de lancer tous les services dans leurs propres CGroup, cela permet de résoudre une bonne fois pour toutes les problèmes d’échappement des processus.
Et encore une fois fournit un outil pour nous aider :
| |